谷歌新研究 让失语者在视频会议中用手语自然交流
视频会议对所有人开放,那也应该包括使用手语进行交流的用户,但由于大多数视频会议系统会自动跟踪讲话人提示窗口,对于手语交流者而言,他们却很难轻松有效地进行沟通。
因此,在视频会议中采用实时手语检测的场景变得十分有挑战性,系统需要使用大量视频反馈作为输入进行分类,这使得任务计算变得十分繁重。某种程度上,这些挑战的存在也导致有关手语检测的研究很少。
近日在ECCV 2020和SLRTP 2020全球顶会上,谷歌的研究团队提出了一个实时手语检测模型,并详述了该模型将如何用于视频会议系统中识别“发言人”的过程。

1、设计思路
为了主动适配主流视频会议系统所提供的会议解决方案,研究团队采取了一种轻量型、即插即用的模型。该模型占用CPU小,以最大程度降低对客户端通话质量的影响。为了减少输入的维度,采用从视频中分离所需信息,对每个帧进行分类。
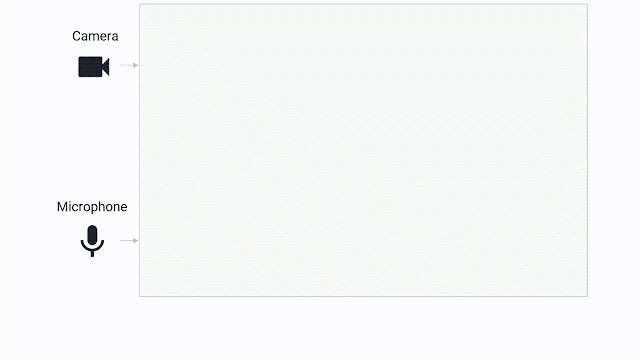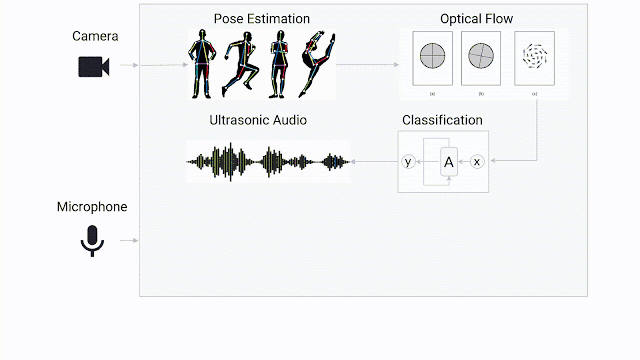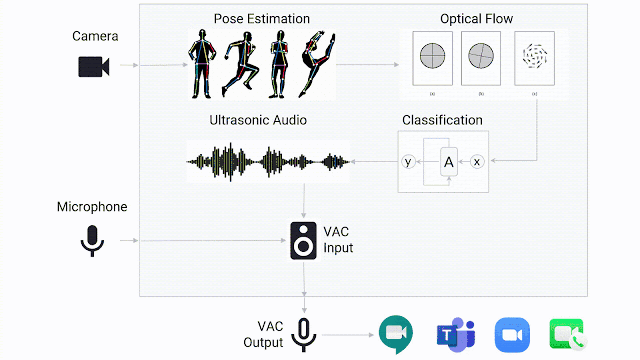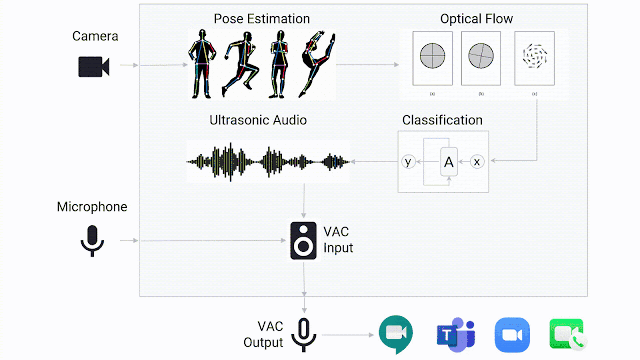
“由于手语涉及用户的身体和手两部分,我们先运行了人体姿态估计模型PoseNet,这样可将输入从整个高清图像大幅分减到用户身体上的一小部分,如眼睛、鼻子、肩膀、手等关键特征点(landmarks)。然后,我们再将这些关键特征点用于计算每一帧光流(Optical Flow),从而在不保留用户特定信息的前提下就能量化用户的姿态特征。每个姿态都通过人肩膀宽度进行归一化,以确保模型在距离摄像头一定距离内注意到用户的手势。最后,将光流通过视频的帧速率进行归一化,再传递给该模型。”
为了测试这种方法的有效性,研究团队采用了德语手语语料库(DGS),该语料库包含人体手势的长视频(含跨度注释)。基于训练好的线性回归模型基线,使用光流数预测人体手势何时发出。该模型基线可达到80%的准确度,每一帧仅需要约3μs(0.000003秒)的处理时间即可完成。通过将前50个帧的光流作为该模型的上下文,最终达到83.4%的准确度。
团队使用了长短期记忆网络(LSTM)架构,该模型可实现的91.5%的准确度,每一帧的处理时间约为3.5毫秒(0.0035秒)。

2、概念验证
在实际的场景中,有了运行完备的手语检测模型仅是第一步,团队还需要设计一种方法来出发视频会议系统的主动式扬声器功能。团队开发了一款轻量级的在线手语检测演示demo,可以连接到任何视频会议系统上,并将手语交流者设置为“发言人”。
当手势检测模型确定用户正在进行手语交流时,它会通过虚拟音频电缆传递超声音频,任何视频会议系统都可检测到该音频,就好像手语交流者正在“讲话”一样。音频以20kHz传输,通常在人类听觉范围之外。因为视频会议系统通常将音频的音量作为检测是否正在讲话的标准,而不是检测语音,所以应用程序会误以为手语交流者正在讲话。
目前这款模型的在线视频演示源代码已经公布在GitHub上。
GitHub传送门:https://github.com/AmitMY/sign-language-detector
3、演示过程
在视频中,研究团队演示了如何使用该模型。视频中的黄色图表反映了模型在检测到手语交流时的确认值。当用户使用手语时,图表值将增加到接近100,当用户停止使用手语时,图表值将降低至0。

为了进一步验证该模型效果,团队还进行了一项用户体验反馈调查。调研要求参与者在视频会议期间使用该模型,并像往常一样进行手语交流。他们还被要求互相使用手语,以检测对说话人的切换功能。反馈结果是,该模型检测到了手语,将其识别为可听见的语音,并成功识别了手势参与人。
从目前来看,此次尝试的出发点及过程中采用的一系列方法的可操作性均本着场景落地为出发点,尽管从实际应用中可能还会出现更多意想不到的海量用户需求,如不同国家地区的手语存在巨大差异等问题,如何将这些能力抽象出来满足更多的人群,将是接下来对这项工作能在商业环境中真正落地需要积极思考的方向。
编辑:齐少恒
相关热词搜索: 让失语者在视频会议中用手语自然交流
上一篇:谷歌日本泄露Pixel 5价格 比前代更便宜 下一篇:机构称OPPO明年手机出货量排第三 华为跌至第七位






