英伟达Feynman GPU前瞻
12 月 30 日消息,科技媒体 Wccftech 昨日(12 月 29 日)发布博文,报道称英伟达计划在 2028 年推出的“费曼”(Feynman)GPU 中,集成 Groq 的 LPU(语言处理单元)技术,意图借此主导 AI 推理市场。

图源:Wccftech
理查德・费曼(Richard Feynman,1918-1988)是美国著名理论物理学家、诺贝尔奖得主,以其在量子电动力学(QED)上的贡献,特别是提出了费曼图而闻名,他因该工作与施温格、朝永振一郎共同获得 1965 年诺奖。
GPU 领域专家 AGF 于 12 月 28 日在 X 平台分析预测,Feynman GPU 将借鉴 AMD 在 X3D 处理器上的成功经验,极有可能采用台积电先进的 SoIC(系统整合芯片)混合键合技术,实施 3D 堆叠设计。

根据这一构想,主计算裸片(compute die,包含 Tensor 单元与控制逻辑)将采用台积电最先进的 A16(1.6nm)工艺制造,而包含大规模 SRAM(静态随机存取存储器)存储库的 LPU 单元则会制成独立的 Die,直接堆叠在计算核心之上。
这种设计利用了 A16 工艺的“背面供电”特性,释放了芯片正面空间用于垂直连接,从而实现超低延迟的数据传输。
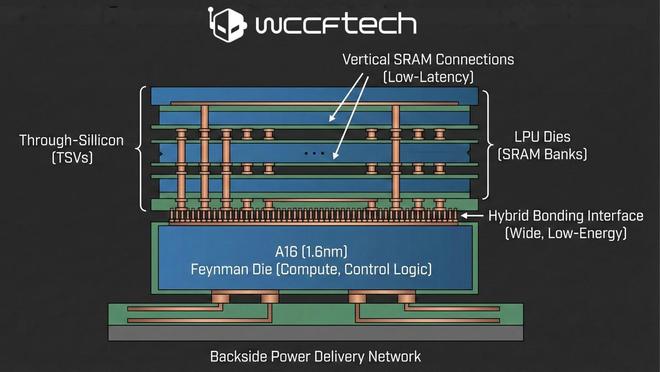
图源:Wccftech 利用 AI 制作生成
该专家分析认为英伟达之所以考虑这种复杂的堆叠方案,主要源于物理层面的限制。随着制程工艺不断微缩,SRAM 的缩放速度已明显滞后于逻辑电路。
如果在昂贵的先进制程节点上制造单片式的大容量 SRAM,不仅会造成高端硅片的浪费,还将导致晶圆成本急剧飙升。因此,将 LPU / SRAM 剥离为独立 Die 并进行堆叠,成为平衡性能与成本的最优解,这也符合当前半导体行业追求“芯粒”(Chiplet)化的技术趋势。
IT之家援引博文介绍,尽管堆叠方案理论上能带来巨大的推理性能飞跃,但实际落地仍面临重重困难。首先是散热问题,在原本就高密度的计算核心上再堆叠发热单元,极易触碰热功耗墙。
其次是更为棘手的软件适配问题:Groq 的 LPU 架构强调“确定性”执行顺序,而英伟达赖以生存的 CUDA 生态则基于硬件抽象与灵活性设计。

图源:Groq
如何在保证 CUDA 兼容性的前提下,完美融合 LPU 的固定执行逻辑,将是英伟达工程师必须攻克的“工程奇迹”。
编辑:齐少恒
相关热词搜索:






